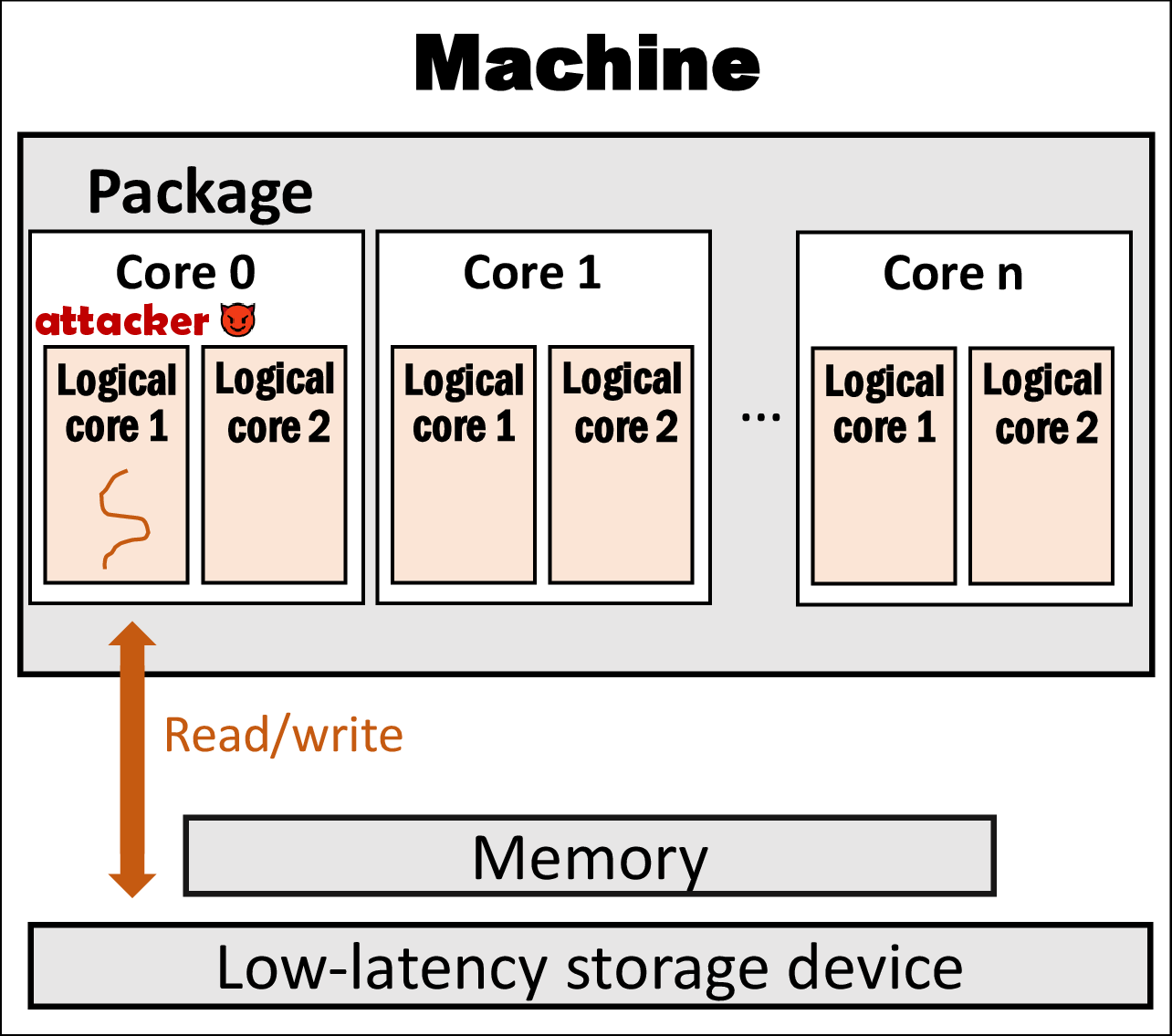
 (a) Attacker (receiver) performing file I/Os alone
(a) Attacker (receiver) performing file I/Os alone
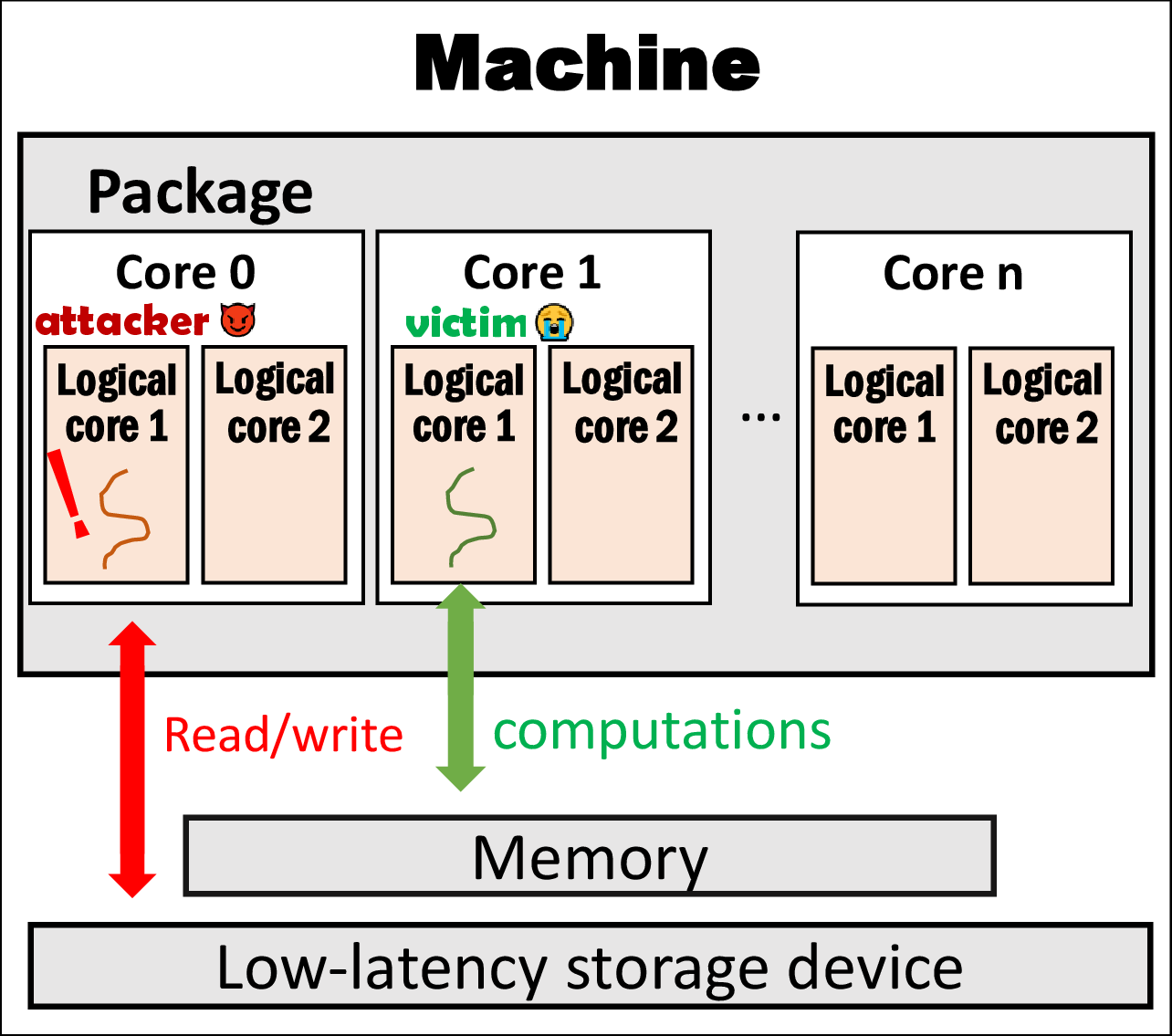 (b) Attacker (receiver) co-existing with victim (sender)
(b) Attacker (receiver) co-existing with victim (sender)
IOLeak: Side-channel Information Leakage with CPU Frequency Scaling, but without CPU Frequency
CPU frequency scaling is widely employed to dynamically adjust the speed and voltage of CPU cores in real time, aiming to achieve both high performance and power efficiency. Prior work indicates that variations in CPU frequency can leak information about the workload being processed. We find that the performance of I/O requests, such as file I/Os with a fast storage device, is affected by runtime changes in CPU frequency and, in turn, reflects the behavior of the ongoing workload.
Accordingly, we develop IOLeak, a new side-channel built on CPU frequency scaling without directly accessing CPU frequency. We first construct an IOLeak covert channel by detecting I/O latency online for secretive communication, both with and without noise. Next, we leverage IOLeak to launch stealthy attacks, such as extracting cryptographic keys and fingerprinting websites, and confirm that IOLeak manages to leak information through file I/Os.
Power efficiency is increasingly critical in computer systems, with CPUs being major power consumers. Dynamic voltage and frequency scaling (DVFS) allows CPUs to adjust their clock frequencies based on the workloads they are serving, particularly reducing power consumption for non-compute-intensive, inactive tasks [14, 28, 37, 46]. I/O operations involving peripheral devices have long been considered appropriate events for triggering CPU frequency reduction [15, 20]. Recently, Linux kernel developers discovered that computations following short-term I/O operations suffer from low CPU frequencies, which may severely impair I/O performance. To address this, they introduced an iowait boosting algorithm [10, 38, 39]. If continuous I/O events are observed in a time tick, the algorithm boosts the CPU frequency to more quickly handle I/O operations and subsequent computations.
Recent studies reveal that CPU frequency fluctuations can be utilized for side-channel attacks, leaking sensitive information from ongoing workloads [30, 31, 33, 34]. However, existing attacks require privileged access to CPU registers or OS interfaces such as scaling_cur_freq [6, 34].
In this paper, we present IOLeak, a novel side-channel attack that exploits CPU frequency scaling through I/O operations without requiring direct CPU frequency access. Our approach is based on the observation that I/O performance—especially on storage devices such as solid-state drives (SSDs)—correlates with CPU frequency changes, enabling adversaries to infer workload characteristics.
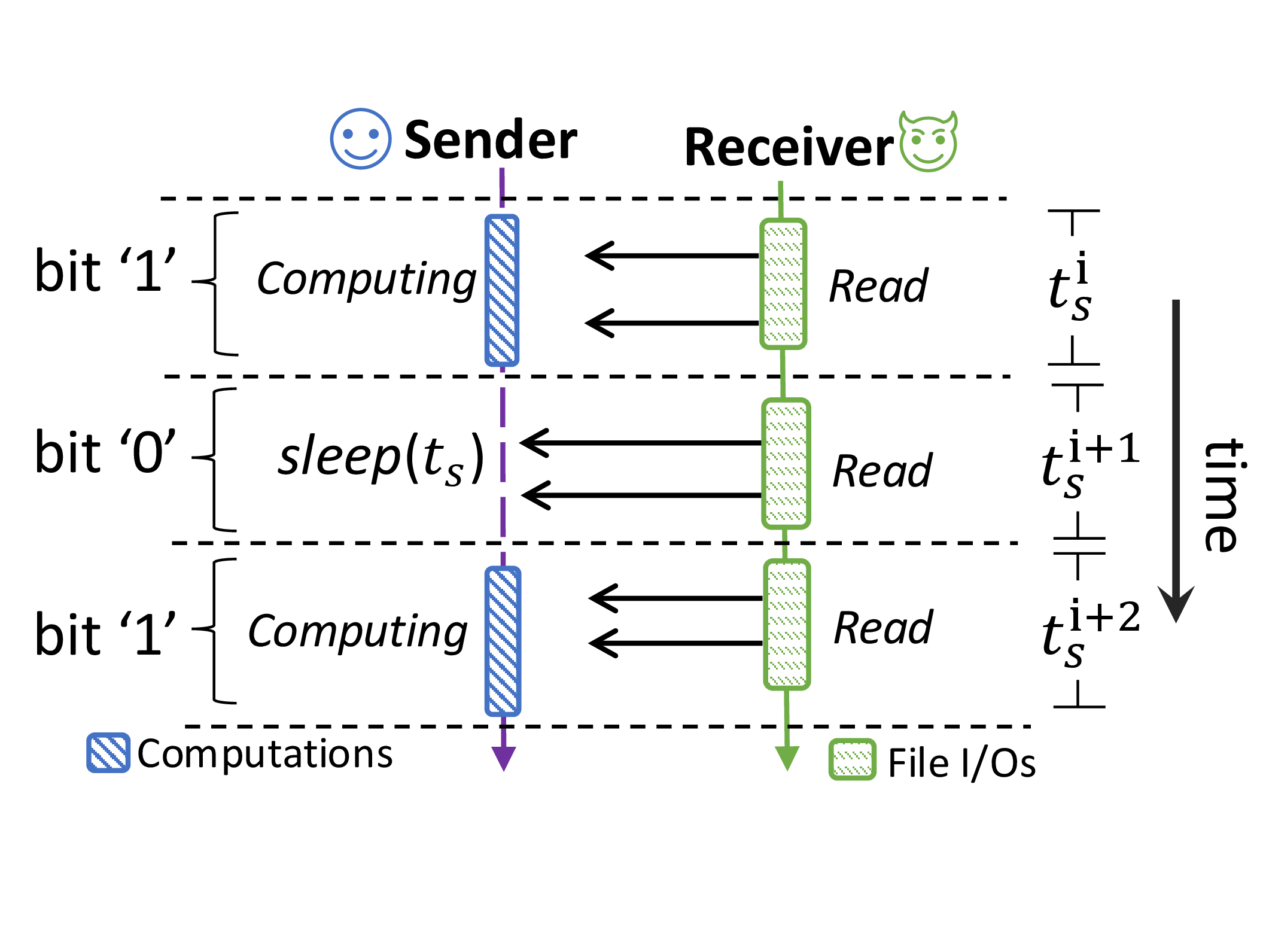
To the best of our knowledge, IOLeak is the first approach leveraging I/O behavior to speculate on CPU frequency changes. We first build a covert channel where a sender manipulates CPU frequency via compute-intensive tasks, while a receiver monitors file I/O latency to detect transmitted information (see Figure 1). We evaluate its effectiveness in the cross-core scenario, achieving a transmission rate of 15.83 bps with a 0.57% bit error rate— comparable to existing CPU frequency-based covert channels. More importantly, we demonstrate that real-world applications, including cryptographic encapsulation/decapsulation and website browsing, are vulnerable to information leakage through IOLeak.
We summarize the contributions of IOLeak as follows:
Let us briefly review CPU frequency scaling and its interaction with I/O performance. Due to the high popularity of Intel CPUs, we mainly focus on Intel's recent products, such as Alder Lake and Xeon Ice Lake-SP, in this paper.
(a) Attacker (receiver) performing file I/Os alone
(b) Attacker (receiver) co-existing with victim (sender)
P-States. A computer comprises CPU, memory, storage, and peripheral devices. Among these, the CPU accounts for a large proportion of the system's overall power consumption. Intel defines the concept of Performance States (P-States), where a CPU core operates at a specific frequency and voltage [5, 40]. Modern CPUs support hardware-managed P-States (HWP), allowing the processor to autonomously manage frequency scaling, reducing the need for OS-controlled CPU frequency adjustments (CPUFreq) [5, 40]. In Linux, CPUFreq implements DVFS to minimize power consumption by adjusting P-States according to workload needs. For compute-intensive tasks, the OS increases CPU frequency and voltage, while for less demanding workloads, it reduces them. This dynamic scaling aims to balance performance and power efficiency.
Frequency Scaling and I/Os. For Linux and Intel CPUs, Intel provides a driver named intel_pstate
[41] which offers several algorithms called scaling governors to determine the desired CPU frequency for a given workload. The default governor is powersave, which strives to balance power savings with high performance. It adjusts the CPU frequency based on workload intensity. We use the powersave governor from the latest stable Linux kernels in our study.
I/O-intensive workloads were traditionally seen as CPU-independent, leading to frequency scale-down. However, Linux developers observed that short-term I/O operations often require subsequent CPU processing. Operating at a low CPU frequency in such cases degrades performance [2, 38]. To address this, the iowait boosting algorithm was added to scaling governors. It temporarily increases CPU frequency when multiple I/O requests occur in a short time window [40]. This algorithm was introduced to prevent performance degradation in post-I/O computations, and as a side effect, it boosts I/O performance itself [2, 16].
| Machine | CPU | Storage Device |
|---|---|---|
| M1 | 12th Gen Intel® Core™ i5-12500 (6 physical cores) | Intel 660p NVMe SSD (512GB) |
| M2 | Intel® Xeon® Gold 6348 (28 physical cores) | Samsung PM863a SATA SSD (960GB) |
To verify whether CPU frequency indeed impacts I/O performance and infer the current CPU frequency, we conducted a suite of tests.
Setup. Figure 1 illustrates the high-level architecture of the machine we studied. Table 1 presents the two machines (M1 and M2) we used. Each machine is equipped with an SSD for unprivileged, ordinary use.
To avoid interfering with these SSDs, we installed Ubuntu 22.04.5 with the built-in Linux kernel 6.8.0-51 on a separate disk for each machine. For all three SSDs, the file system is Ext4, mounted in the default data=ordered mode. We primarily use the default powersave governor of intel_pstate for frequency scaling and manually set a specific frequency using the userspace governor when necessary.
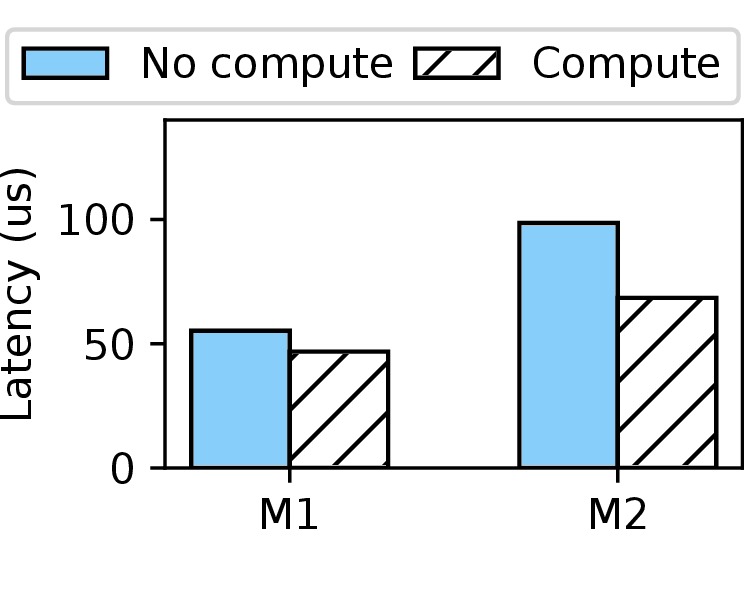
powersave mode with and without computing tasks
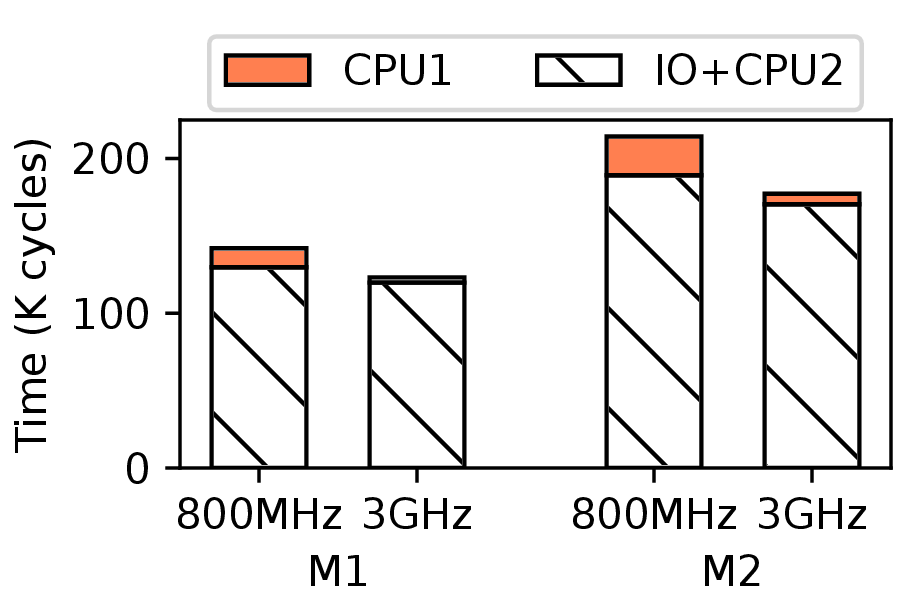
Tests. In the first test, we fix the CPU frequency at 800 MHz and 3 GHz using the userspace governor. On both SSDs of M1 and M2, we create a file with only one data block of 4KB and consider an I/O pattern that repeatedly reads this block in direct I/O (O_DIRECT) mode. This file has the simplest structure, minimizing both the cost of mapping from in-file offset to on-disk block number [42] and the internal contention in an SSD [19]. The direct I/O mode rules out the divergence caused by the OS's page cache. For ease of analysis, we use the rdtscp instruction of x86 to measure the average I/O latency in terms of CPU clock cycles consumed per read I/O request. In Figure 2a, each SSD has two bars corresponding to the two frequencies. For both SSDs, their I/O latencies reduce by 13.2% and 17.2%, respectively. Therefore, the change in CPU frequency results in noticeably different I/O performances. Although these performance variations are moderate, we will demonstrate that they cause severe information leakage.
To understand why CPU frequency affects I/O latency, we decompose the procedure of an I/O request delivered through the read system call (syscall) to the SSD. The procedure consists of two stages. The first stage translates the read syscall to the kernel-space function of the specific file system, i.e., Ext4's ext4_dio_read_iter. Ext4 locates the target disk block, makes a block I/O (bio) request, and submits it to the bio layer. In the second stage, the bio layer issues that bio request to the device driver, waits for and collects the return value from the SSD, and forwards the completion or failure signal to the user-space program. The first stage involves CPU computations, while the second stage primarily occurs inside the SSD, though it also requires some CPU involvement. We refer to these two stages as CPU1 and IO+CPU2, respectively.
Figure 2a shows the breakdown of clock cycles spent on the two stages for both SSDs at the two frequencies. For example, when the CPU frequency increases from 800 MHz to 3 GHz on M1, the execution time for the CPU1 stage decreases by 73.3%. The execution time for the IO+CPU2 stage also reduces by 7.6%. The acceleration of computations in both stages explains why changes in CPU frequency impact I/O latencies for both SSDs.
In the second test, we switch back to the default powersave governor of intel_pstate. We evaluate whether I/O performance fluctuates when CPU frequency scaling happens dynamically. We repeat the same I/O pattern on both machines. To trigger frequency scaling, we create a thread that performs heavy computations such as random number generation or matrix multiplication. We run the I/O task with and without the presence of this computing task. As shown in Figure 2b, when the CPU frequency scales up due to the computing task, the average I/O latency decreases by 15.2% and 30.6% on M1 and M2, respectively. This motivates us to study the runtime changes of I/O performance more deeply.
Researchers have built covert (side) channels by directly exploiting CPU frequency, since different running workloads, or one workload with different data processed, cause observable variations in runtime CPU frequency [13, 22, 34, 35, 47]. In contrast to these works utilizing hardware registers or specific interfaces provided by the OS, the storage I/O performance, as verified by our tests in Section 3, provides an inconspicuous and controllable viewpoint to online monitor changes in CPU frequency and, in turn, infer information about ongoing workloads. Using this observation, we build a covert channel for communication. We name it IOLeak. IOLeak is a timing-based channel as it transmits data by measuring I/O response latency over time.
Figure 3 shows the workflow of the IOLeak covert channel in transmitting data. Two parties, the receiver and the sender, rely on the channel for secret communication. They run concurrently as two user-space programs (processes) on the same multi-core CPU. Except for the CPU, they do not need to share any specific hardware, such as CPU cache lines or sets [24, 44], cache coherence directories [43], TLBs [12], or other components [8, 25, 36]. In particular, although the receiver measures the I/O response latency at runtime, the two parties do not have to share the same storage device during communication [18, 19]. They also do not need to share any software structures or libraries [21, 26, 27, 44]. The sender and receiver can run on the same CPU core or different cores. We intentionally allocate different physical cores to them for meaningful covert communications.
Setup. We adhere to the default powersave governor of
intel_pstate for CPU frequency scaling. The sender and receiver agree that the sender delivers one bit of information
to the receiver in each fixed time window (i.e., symbol duration). For reliable communication,
we let the sender create κ threads (κ > 0), each running on a separate physical core.
Following the study shown in Section 3, the receiver prepares a 4KB file and reads the data in direct I/O mode.
Moreover, the receiver maintains a profile of expected higher and lower I/O latencies to distinguish transmitted bits.
Protocol. Since this is a covert channel for communication, the two parties can calibrate and synchronize before actual transmission. To send a bit '1', the sender engages κ threads performing compute-intensive tasks, such as generating random integers. Conversely, to send a bit '0', the sender remains idle by sleeping during the time window t. On the receiving side, the receiver attempts to obtain the transmitted bit during the same time window by repeatedly loading the file data directly from storage. If a longer I/O latency is observed, a bit '0' is received, as the CPU frequency remains low due to the sender's inactivity. A shorter I/O latency indicates a bit '1', since the sender's active computing tasks increase the CPU frequency.
| Time window size (ms) | 30 | 60 | 90 | |
|---|---|---|---|---|
| Noiseless | Capacity (bps) | 15.47 | 15.83 | 11.11 |
| BER | 12.23% | 0.57% | 0% | |
| Compute-intensive noise | Capacity (bps) | 0.004 | 2.37 | 5.19 |
| BER | 49.28% | 28.17% | 12.12% | |
| I/O-intensive noise | Capacity (bps) | 0.03 | 14.70 | 7.55 |
| BER | 48.13% | 1.60% | 5.83% | |
Evaluation. Let us evaluate the performance of the IOLeak covert channel. Without loss of generality, we mainly present the results obtained on machine M1, where the sender process includes three threads (i.e., κ = 3) concurrently performing compute-intensive tasks on three physical cores. We have tested three sizes for the time window: t = 30 ms, 60 ms, and 90 ms. The reason we chose a millisecond-level time window (symbol duration) is that with modern CPUs and the Linux kernel, the online adjustment to scale CPU frequency up or down occurs every one or multiple milliseconds. Prior works based on power management used a similar time window [16, 48]. Therefore, our setting of the time window t is compatible and sound.
We make the sender continuously send 1,000 bits. To measure channel performance, we use two common metrics: bit error rate (BER) and channel capacity. We denote the channel capacity as T and calculate it using the following binary symmetric channel model [11, 18, 45]:
In this formula, C is the raw bit rate (1/t) and p is the BER.
As shown in the upper rows of Table 2, with the three time window sizes, the channel capacity of IOLeak is 15.47 bps, 15.83 bps, and 11.11 bps, respectively. IOLeak achieves a comparable capacity against covert channels built directly on power management (18.7 bps [22]) and frequency scaling (46 bps [13]). Correspondingly, the BERs of IOLeak decrease to 12.23%, 0.57%, and 0.00% with the increasing window sizes. With a longer time window (60 ms and 90 ms), the receiver has more sufficient time to detect and process each change in CPU frequency.
In this section, we create several stealthy IOLeak side-channels and initiate cross-core attacks to demonstrate potential information leakage. We aim to prove that the IOLeak side-channel is capable of extracting cryptographic keys and revealing information about actively visited websites.
We assume that the two parties in an attack, i.e., the attacker and the victim, are two user-space, unprivileged processes. Similar to Section 4, they do not need to run on the same core. Also, they do not need to share any data, libraries, or particular hardware or software structures. For the attacker, we prepare a file with only one 4KB-sized block prefilled with random data. Then, we launch the attacker process that continuously reads data in direct I/O mode. We use runtime changes of I/O latency to infer secrets of the victim process. The attacker is allowed to have a profile of I/O latencies expected at different CPU frequencies. In this section, we establish that our I/O-based cross-core side-channel possesses the same capability as CPU frequency-based side-channels.
Extracting Cryptographic Keys.
The first target of the IOLeak side-channel is to extract cryptographic keys used in the Supersingular Isogeny Key Encapsulation (SIKE). SIKE is a widely studied post-quantum key encapsulation mechanism based on the Supersingular Isogeny Diffie-Hellman (SIDH) key exchange protocol [17]. A SIKE user decapsulates one or multiple ciphertexts with a static secret key. For this decapsulation, the SIKE standard employs an efficient algorithm known as the Montgomery three-point ladder [9]. Wang et al. [34] demonstrated that SIKE is vulnerable under the chosen-ciphertext attack (CCA) model, in which the attacker generates many ciphertexts and asks the victim to decapsulate them, allowing the attacker to guess the key based on his/her observations. Wang et al. [34] managed to extract secret keys by monitoring CPU frequency variations. We, as an attacker using IOLeak, aim to recover such keys by conducting file I/Os.
Because of space limitations, we briefly describe the steps relevant to CPU frequency during the SIKE decapsulation procedure. More details can be found in related works [3, 35, 34]. The victim's secret key, denoted as m, is composed of ℓ bits (ℓ = 378 in this attack case). For each target bit mi in m used in the (i - 1)th round of the Montgomery three-point ladder, if mi ≠ mi - 1, an anomalous zero value will be produced, causing the decapsulation procedure to get stuck and continuously produce zero values, resulting in the CPU running at a higher frequency. Conversely, if mi = mi - 1, no anomalous zero value appears, and the CPU operates at a lower frequency. The attacker repeatedly queries the victim's decapsulation procedure with crafted ciphertexts following the CCA model, while monitoring the real-time I/O latency of reading file data to infer whether the decapsulation procedure gets stuck or not. If the attacker observes a shorter I/O latency relative to their profile, indicating a higher CPU frequency, they deduce that mi ≠ mi - 1, meaning these two bits have opposite values. Otherwise, if the I/O latency is longer, then mi = mi - 1, indicating they are both '0's or both '1's. By observing through the IOLeak side-channel, the attacker can identify the secret key bits.
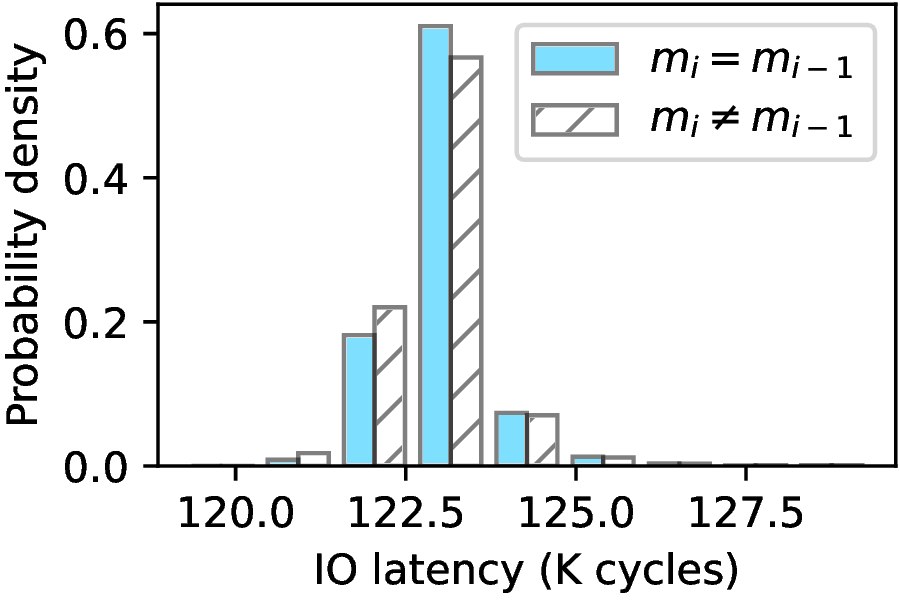 (a) Attack to PQCrypto-SIDH
(a) Attack to PQCrypto-SIDH
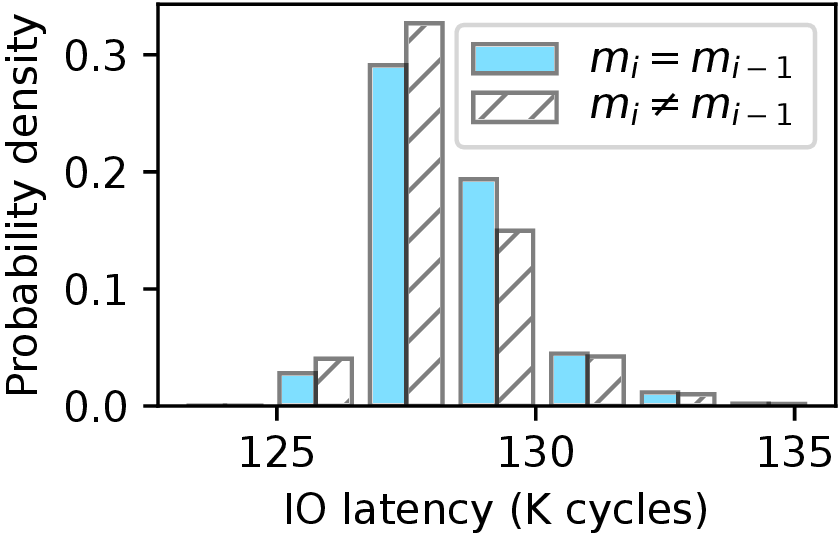 (b) Attack to CIRCL
(b) Attack to CIRCL
For the SIKE implementation used by the victim, we take Microsoft's PQCrypto-SIDH [29] and Cloudflare's Interoperable Reusable Cryptographic Library (CIRCL) [1]. Without loss of generality, we evaluate 10 randomly generated keys, targeting 4 out of the 378 bit positions in each key. For every key and its target bits, we launch a decapsulation server process using POSIX threads (pthreads) for PQCrypto-SIDH or 300 goroutines for CIRCL, each handling a single decapsulation request. To minimize IOLeak's impact on increasing CPU frequency, the attacker samples at 1 ms intervals as in [34], which may cause the sampling duration to exceed the normal completion time of I/O requests. IOLeak collects 200,000 samples over 200 seconds for each guess.
The two diagrams in Figure 4 correspond to the results for two SIKE implementations, respectively, on machine M1. The X-axis shows the I/O latency measured by the attacker in kilo (K) clock cycles, while the Y-axis represents the probability density. As demonstrated in Figure 4, the I/O latency is lower when an anomalous zero value is triggered (i.e., mi ≠ mi-1) than when the zero value does not occur (i.e., mi = mi-1). Thus, IOLeak enables the attacker to significantly reduce the search space when speculating the key's bits. Based on this insight, IOLeak reduces the time complexity of guessing a target secret key from O(2n) to O(n), dramatically improving the feasibility of recovering the entire key used in the SIKE mechanism.
Website fingerprinting is commonly used to assess the capability of a side-channel because various websites exhibit different behaviors across multiple dimensions, such as network traffic [4], CPU cache contention [32], shared OS kernel structures [27], power consumption [22,48], and even the fsync syscall [18]. Our focus is on the fact that various websites have different visual appearances, which induce varying graphical activities in webpage loading and image rendering, leading to distinct patterns of CPU frequency [6, 7, 34] and, in turn, different variations of I/O latency.
We construct a side-channel attack with IOLeak, targeting the two most commonly used browsers, Google Chrome and Mozilla Firefox. The victim opens a website from the Alexa Top 100 and waits for five seconds, offering sufficient time for the website to be fully loaded. The attacker leverages IOLeak to sample every 1 ms, ultimately obtaining 5000 data points. For classification, these raw traces are processed and fed into a Long Short-Term Memory (LSTM) model with 16 units after normalization. Table 3 presents the Top-1 and Top-5 accuracies with both browsers on three machines. With M1, the Top-1 accuracy reaches 79.4% when using Google Chrome, demonstrating a high probability of correctly inferring the expected website. The Top-5 accuracy is as high as 97.5%, comparable to prior works directly exploiting CPU frequency [6] and much higher than those relying on CPU cache contention [32]. With M2, the accuracies fluctuate lower than with M1 but remain much higher than random guessing (1% for Top-1 and 5% for Top-5 accuracy). A deep analysis on these fluctuations shows that changes in CPU frequency on one core have less impact on other cores in M2, weakening the effect of cross-core IOLeak attacks.
| Metric | Google Chrome | Mozilla Firefox | ||
|---|---|---|---|---|
| Top-1 | Top-5 | Top-1 | Top-5 | |
| M1 | 79.4% | 97.5% | 65.5% | 83.0% |
| M1 | 48.2% | 76.7% | 46.4% | 77.0% |
The security breach revealed by IOLeak is significant. One mitigation approach involves running compute-intensive and/or I/O-intensive background tasks to introduce noise, which can degrade IOLeak's accuracy. Another strategy is to fix the CPU frequency to prevent information leakage via frequency scaling. However, this undermines dynamic frequency scaling's core purpose — balancing power efficiency and performance.
Since IOLeak exploits file I/O latency, injecting noise into the storage I/O path or stabilizing latency by normalizing it to a consistent value can be effective. These approaches, however, will likely degrade I/O performance, negatively impacting benign user experience.
Application-specific mitigations are also feasible. For example, to defend against CCA-style attacks on the SIKE implementation, validations can be added to prevent attackers from issuing malicious requests [3]. In the case of website fingerprinting, browsers can enforce standardized rendering behaviors across websites, making it more difficult for side-channel attacks like IOLeak to differentiate between them.
As mentioned, AMD CPUs also support scaling governor algorithms, defined in the amd-pstate driver [49]. We evaluated IOLeak on a machine equipped with an AMD Ryzen 5 9600X CPU (x86-64, six cores) and a Kingston SSDNow V300 NVMe SSD (1TB). The communication setup between two parties mirrored that described in the previous section, and we again varied the time window (symbol duration).
Table 4 details the capacity and BER of the cross-core covert channel. For instance, with a 60 ms time window, the capacity and BER reached 13.92 bps and 2.43%, respectively.
We also replicated the website fingerprinting attack using the Google Chrome browser. The TOP-1 and TOP-5 accuracies for identifying websites from the Alexa Top 100 were 61.4% and 84.7%, respectively. These findings confirm IOLeak's effectiveness on AMD platforms. We plan to extend testing to other architectures, such as ARM and RISC-V CPUs.
| Time window size (ms) | 30 | 60 | 90 | 120 |
|---|---|---|---|---|
| Capacity (bps) | N/A | 13.92 | 10.62 | 8.17 |
| BER | N/A | 2.43% | 0.48% | 0.18% |
We revisited the potential of side-channel attacks through CPU frequency scaling — without directly monitoring the frequency. We proposed IOLeak, a timing-based channel that leverages the impact of real-time CPU frequency on storage I/O latency, thereby indirectly leaking information about concurrent workloads.
Using IOLeak, we demonstrated the feasibility of covert communication across CPU cores, as well as two practical side-channel attacks: one targeting cryptographic key extraction and the other enabling website fingerprinting. Should you have any question, please drop an email to cd_wang "the-at-sign" outlook.com.
In future work, we plan to investigate IOLeak's applicability in cross-virtual machine (VM) leakage scenarios, a topic insufficiently addressed by prior research. We hope our contributions will stimulate continued research and innovation in this critical area.
[1] Cloudflare. 2024. CIRCL: Cloudflare Interoperable, Reusable Cryptographic Library. https://github.com/cloudflare/circl.git . Accessed: 2024-12-30.
[2] Jonathan Corbet. 2024. The trouble with iowait. https://lwn.net/Articles/989272/ . Accessed: 2025-01-06.
[3] Luca De Feo, Nadia El Mrabet, Aymeric Genêt, Novak Kaluđerović, Natacha Linard de Guertechin, Simon Pontié, and Élise Tasso. 2022. SIKE channels: Zero-value side-channel attacks on SIKE. IACR Transactions on Cryptographic Hardware and Embedded Systems 2022 (2022), 264-289.
[3] Luca De Feo, Nadia El Mrabet, Aymeric Genêt, Novak Kaluđerović, Natacha Linard de Guertechin, Simon Pontié, and Élise Tasso. 2022. SIKE channels: Zero-value side-channel attacks on SIKE. IACR Transactions on Cryptographic Hardware and Embedded Systems 2022 (2022), 264-289.
[5] Kevin Devey, David Hunt, and Chris MacNamara. 2022. Intel Power Management - Technology Overview. https://networkbuilders.intel.com/solutionslibrary/power-management-technology-overview-technology-guide . Accessed: 2025-01-06.
[6] Debopriya Roy Dipta and Berk Gulmezoglu. 2022. DF-SCA: Dynamic Frequency Side Channel Attacks are Practical. In Proceedings of the 38th Annual Computer Security Applications Conference (Austin, TX, USA) (ACSAC ’22) . Association for Computing Machinery, New York, NY, USA, 841-853. https://doi.org/10.1145/3564625.3567979
[7] Debopriya Roy Dipta, Thore Tiemann, Berk Gulmezoglu, Eduard Marin, and Thomas Eisenbarth. 2024. Dynamic Frequency-Based Fingerprinting Attacks against Modern Sandbox Environments. In 2024 IEEE 9th European Symposium on Security and Privacy (EuroS&P). 327–344. https://doi.org/10.1109/EuroSP60621.2024.00025
[8] Dmitry Evtyushkin, Ryan Riley, Nael CSE Abu-Ghazaleh, ECE, and Dmitry Ponomarev. 2018. BranchScope: A New Side-Channel Attack on Directional Branch Predictor. In Proceedings of the Twenty-Third International Conference on Architectural Support for Programming Languages and Operating Systems (Williamsburg, VA, USA) (ASPLOS ’18) . Association for Computing Machinery, New York, NY, USA, 693–707. https://doi.org/10.1145/3173162.3173204
[9] Armando Faz-Hernández, Julio López, Eduardo Ochoa-Jiménez, and Francisco Rodríguez-Henríquez. 2018. A Faster Software Implementation of the Supersingular Isogeny Difie-Hellman Key Exchange Protocol. IEEE Trans. Comput. 67, 11 (2018), 1622–1636. https://doi.org/10.1109/TC.2017.2771535
[10] Joel Fernandes and Peter Zijlstra. 2017. [v2,1/2] cpufreq: Make iowait boost a policy option - Patchwork — google.com. https://patchwork.kernel.org/project/linux-pm/patch/20170519062344.27692-2-joelaf@google.com/ .
[11] Steven Gianvecchio, Haining Wang, Duminda Wijesekera, and Sushil Jajodia. 2008. Model-Based Covert Timing Channels: Automated Modeling and Evasion. In Recent Advances in Intrusion Detection , Richard Lippmann, Engin Kirda, and Ari Trachtenberg (Eds.). Springer Berlin Heidelberg, Berlin, Heidelberg, 211–230.
[12] Ben Gras, Kaveh Razavi, Herbert Bos, and Cristiano Giuffrida. 2018. Translation Leak-aside Buffer: Defeating Cache Side-channel Protections with TLB Attacks. In 27th USENIX Security Symposium (USENIX Security 18) . USENIX Association, Baltimore, MD, 955–972. https://www.usenix.org/conference/usenixsecurity18/presentation/gras
[13] Yanan Guo, Dingyuan Cao, Xin Xin, Youtao Zhang, and Jun Yang. 2023. Uncore Encore: Covert Channels Exploiting Uncore Frequency Scaling. In Proceedings of the 56th Annual IEEE/ACM International Symposium on Microarchitecture (Toronto, ON, Canada) (MICRO ’23) . Association for Computing Machinery, New York, NY, USA, 843–855. https://doi.org/10.1145/3613424.3614259
[14] Vishal Gupta, Paul Brett, David Koufaty, Dheeraj Reddy, Scott Hahn, Karsten Schwan, and Ganapati Srinivasa. 2012. The Forgotten ‘Uncore’: On the Energy-Efficiency of Heterogeneous Cores. In 2012 USENIX Annual Technical Conference (USENIX ATC 12) . USENIX Association, Boston, MA, 367–372. https://www.usenix.org/conference/atc12/technical-sessions/presentation/gupta
[15] Shadi Ibrahim, Tien-Dat Phan, Alexandra Carpen-Amarie, Houssem-Eddine Chihoub, Diana Moise, and Gabriel Antoniu. 2016. Governing energy consumption in Hadoop through CPU frequency scaling: An analysis. Future Generation Computer Systems 54 (Jan 2016), 219–232. https://doi.org/10.1016/j.future.2015.01.005
[16] Satoshi IMAMURA, Eiji YOSHIDA, and Kazuichi OE. 2019. Reducing CPU Power Consumption with Device Utilization-Aware DVFS for Low-Latency SSDs. IEICE Transactions on Information and Systems E102.D, 9 (2019), 1740–1749. https://doi.org/10.1587/transinf.2018EDP7337
[17] David Jao and Luca De Feo. 2011. Towards Quantum-Resistant Cryptosystems from Supersingular Elliptic Curve Isogenies. In Post-Quantum Cryptography , Bo-Yin Yang (Ed.). Springer Berlin Heidelberg, Berlin, Heidelberg, 19–34.
[18] Qisheng Jiang and Chundong Wang. 2024. Sync+Sync: A Covert Channel Built on fsync with Storage. In 33rd USENIX Security Symposium (USENIX Security 24) . USENIX Association, Philadelphia, PA, 3349–3366. https://www.usenix.org/conference/usenixsecurity24/presentation/jiang-qisheng
[19] Jonas Jufinger, Fabian Rauscher, Giuseppe La Manna, and Daniel Gruss. 2025. Secret Spilling Drive: Leaking User Behavior through SSD Contention. In Network and Distributed System Security (NDSS) Symposium 2025. https://doi.org/10.14722/ndss.2025.23208
[20] Michael A. Laurenzano, Mitesh Meswani, Laura Carrington, Allan Snavely, Mustafa M. Tikir, and Stephen Poole. 2011. Reducing energy usage with memory and computation-aware dynamic frequency scaling. In Proceedings of the 17th International Conference on Parallel Processing - Volume Part I (Bordeaux, France) (Euro-Par’11). Springer-Verlag, Berlin, Heidelberg, 79–90.
[21] Yoochan Lee, Jinhan Kwak, Junesoo Kang, Yuseok Jeon, and Byoungyoung Lee. 2023. Pspray: Timing Side-Channel based Linux Kernel Heap Exploitation Technique. In 32nd USENIX Security Symposium (USENIX Security 23). USENIX Association, Anaheim, CA, 6825–6842. https://www.usenix.org/conference/usenixsecurity23/presentation/lee-yoochan
[22] Moritz Lipp, Andreas Kogler, David Oswald, Michael Schwarz, Catherine Easdon, Claudio Canella, and Daniel Gruss. 2021. PLATYPUS: Software-based Power Side-Channel Attacks on x86. In 2021 IEEE Symposium on Security and Privacy (SP) . 355–371. https://doi.org/10.1109/SP40001.2021.00063
[23] Chen Liu, Abhishek Chakraborty, Nikhil Chawla, and Neer Roggel. 2022. Frequency Throttling Side-Channel Attack. In Proceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security (Los Angeles, CA, USA) (CCS ’22) . Association for Computing Machinery, New York, NY, USA, 1977–1991. https://doi.org/10.1145/3548606.3560682
[24] Fangfei Liu, Yuval Yarom, Qian Ge, Gernot Heiser, and Ruby B. Lee. 2015. Last-Level Cache Side-Channel Attacks are Practical. In 2015 IEEE Symposium on Security and Privacy . 605–622. https://doi.org/10.1109/SP.2015.43
[25] Sihang Liu, Suraaj Kanniwadi, Martin Schwarzl, Andreas Kogler, Daniel Gruss, and Samira Khan. 2023. Side-Channel Attacks on Optane Persistent Memory. In 32nd USENIX Security Symposium (USENIX Security 23) . USENIX Association, Anaheim, CA, 6807–6824. https://www.usenix.org/conference/usenixsecurity23/presentation/liu-sihang
[26] Lukas Maar, Stefan Gast, Martin Unterguggenberger, Mathias Oberhuber, and Stefan Mangard. 2024. SLUBStick: Arbitrary Memory Writes through Practical Software Cross-Cache Attacks within the Linux Kernel. In 33rd USENIX Security Symposium (USENIX Security 24) . USENIX Association, Philadelphia, PA, 4051–4068. https://www.usenix.org/conference/usenixsecurity24/presentation/maar-slubstick
[27] Lukas Maar, Jonas Jufinger, Thomas Steinbauer, Daniel Gruss, and Stefan Mangard. 2025. KernelSnitch: Side-Channel Attacks on Kernel Data Structures. In Network and Distributed System Security Symposium (NDSS) 2025. https://doi.org/10.14722/ndss.2025.240223 Network and Distributed System Security Symposium 2025 : NDSS 2025, Conference date: 23-02-2025 Through 28-02-2025.
[28] David Meisner, Brian T. Gold, and Thomas F. Wenisch. 2009. PowerNap: eliminating server idle power. In Proceedings of the 14th International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS XIV) , Washington, DC, USA. Association for Computing Machinery, New York, NY, USA, 205–216. https://doi.org/10.1145/1508244.1508269
[29] Microsoft. 2024. PQCrypto-SIKE: Supersingular Isogeny Key Encapsulation. https://github.com/microsoft/PQCrypto-SIKE.git . Accessed: 2024-12-30.
[30] Philipp Miedl, Xiaoxi He, Matthias Meyer, Davide Basilio Bartolini, and Lothar Thiele. 2018. Frequency Scaling As a Security Threat on Multicore Systems. In IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems 37, 11 (2018), 2497–2508. https://doi.org/10.1109/TCAD.2018.2857038
[31] Fabian Rauscher, Andreas Kogler, Jonas Jufinger, and Daniel Gruss. 2024. IdleLeak: Exploiting Idle State Side Effects for Information Leakage. In 31st Annual Network and Distributed System Security Symposium, NDSS 2024, San Diego, California, USA, February 26 - March 1, 2024 . The Internet Society, 1–16. https://www.ndss-symposium.org/ndss-paper/idleleak-exploiting-idle-state-side-effects-for-information-leakage/
[32] Anatoly Shusterman, Lachlan Kang, Yarden Haskal, Yosef Meltser, Prateek Mittal, Yossi Oren, and Yuval Yarom. 2019. Robust Website Fingerprinting Through the Cache Occupancy Channel. In 28th USENIX Security Symposium (USENIX Security 19) . USENIX Association, Santa Clara, CA, 639–656. https://www.usenix.org/conference/usenixsecurity19/presentation/shusterman
[33] Adrian Tang, Simha Sethumadhavan, and Salvatore Stolfo. 2017. CLKSCREW: Exposing the Perils of Security-Oblivious Energy Management. In 26th USENIX Security Symposium (USENIX Security 17) . USENIX Association, Vancouver, BC, 1057–1074. https://www.usenix.org/conference/usenixsecurity17/technical-sessions/presentation/tang
[34] Yingchen Wang, Riccardo Paccagnella, Elizabeth Tang He, Hovav Shacham, Christopher W. Fletcher, and David Kohlbrenner. 2022. Hertzbleed: Turning Power Side-Channel Attacks Into Remote Timing Attacks on x86. In 31st USENIX Security Symposium (USENIX Security 22) . USENIX Association, Boston, MA, 679–697. https://www.usenix.org/conference/usenixsecurity22/presentation/wang-yingchen
[35] Yingchen Wang, Riccardo Paccagnella, Alan Wandke, Zhao Gang, Grant Garrett-Grossman, Christopher W. Fletcher, David Kohlbrenner, and Hovav Shacham. 2023. DVFS Frequently Leaks Secrets: Hertzbleed Attacks Beyond SIKE, Cryptography, and CPU-Only Data. In 2023 IEEE Symposium on Security and Privacy (SP) . IEEE Computer Society, Los Alamitos, CA, USA, 2306–2320. https://doi.org/10.1109/SP46215.2023.10179326
[36] Zixuan Wang, Mohammadkazem Taram, Daniel Moghimi, Steven Swanson, Dean Tullsen, and Jishen Zhao. 2023. NVLeak: Off-Chip Side-Channel Attacks via Non-Volatile Memory Systems. In 32nd USENIX Security Symposium (USENIX Security 23) . USENIX Association, Anaheim, CA, 6771–6788. https://www.usenix.org/conference/usenixsecurity23/presentation/wang-zixuan
[37] Mark Weiser, Brent Welch, Alan Demers, and Scott Shenker. 1994. Scheduling for reduced CPU energy. In Proceedings of the 1st USENIX Conference on Operating Systems Design and Implementation (Monterey, California) (OSDI '94) . USENIX Association, USA, 12–22.
[38] Rafael J. Wysocki. 2016. [GIT PULL] Power management material for v4.9-rc1. https://lore.kernel.org/lkml/CAJZ5v0hcVZSLR+ya-p=WqeYG1mXSz4H=xj9K4hDFRh-c5TOHtQ@mail.gmail.com/ . Accessed: 2024-12-30.
[39] Rafael J. Wysocki. 2016. Linux-Kernel Archive: [RFC][PATCH 0/7] cpufreq / sched: cpufreq_update_util() flags and iowait boosting. https://lkml.iu.edu/hypermail/linux/kernel/1607.3/04060.html .
[40] Rafael J. Wysocki. 2017. CPU Performance Scaling. https://www.kernel.org/doc/html/latest/admin-guide/pm/cpufreq.html . Accessed: 2025-01-06.
[41] Rafael J. Wysocki. 2017. intel_pstate CPU Performance Scaling Driver. https://www.kernel.org/doc/html/latest/admin-guide/pm/intelpstate.html . Accessed: 2024-12-30.
[42] Sujay Yadalam, Chloe Alverti, Vasileios Karakostas, Jayneel Gandhi, and Michael Swift. 2024. BypassD: Enabling fast userspace access to shared SSDs. In Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1 (La Jolla, CA, USA) (ASPLOS '24). Association for Computing Machinery, New York, NY, USA, 35-51. https://doi.org/10.1145/3617232.3624854
[43] Mengjia Yan, Read Sprabery, Bhargava Gopireddy, Christopher Fletcher, Roy Campbell, and Josep Torrellas. 2019. Attack Directories, Not Caches: Side Channel Attacks in a Non-Inclusive World. In 2019 IEEE Symposium on Security and Privacy (SP). 888-904. https://doi.org/10.1109/SP.2019.00004
[44] Yuval Yarom and Katrina Falkner. 2014. FLUSH+RELOAD: A High Resolution, Low Noise, L3 Cache Side-Channel Attack. In 23rd USENIX Security Symposium (USENIX Security 14). USENIX Association, San Diego, CA, 719-732. https://www.usenix.org/conference/usenixsecurity14/technical-sessions/presentation/yarom
[45] Baki Berkay Yilmaz, Nader Sehatbakhsh, Alenka Zajić, and Milos Prvulovic. 2020. Communication Model and Capacity Limits of Covert Channels Created by Software Activities. IEEE Transactions on Information Forensics and Security 15 (2020), 1891-1904. https://doi.org/10.1109/TIFS.2019.2952265
[46] Xiao Zhang, Sandhya Dwarkadas, and Rongrong Zhong. 2010. An Evaluation of Per-Chip Nonuniform Frequency Scaling on Multicores. In 2010 USENIX Annual Technical Conference (USENIX ATC 10). USENIX Association, Boston, MA, 259-264. https://www.usenix.org/conference/usenix-atc-10/evaluation-chip-nonuniform-frequency-scaling-multicores
[47] Xin Zhang, Zhi Zhang, Qingni Shen, Wenhao Wang, Yansong Gao, Zhuoxi Yang, and Jiliang Zhang. 2024. SegScope: Probing Fine-grained Interrupts via Architectural Footprints. In 2024 IEEE International Symposium on High-Performance Computer Architecture (HPCA). 424-438. https://doi.org/10.1109/HPCA57654.2024.00039
[48] Zhenkai Zhang, Sisheng Liang, Fan Yao, and Xing Gao. 2021. Red Alert for Power Leakage: Exploiting Intel RAPL-Induced Side Channels. In Proceedings of the 2021 ACM Asia Conference on Computer and Communications Security (Virtual Event, Hong Kong) (ASIA CCS '21). Association for Computing Machinery, New York, NY, USA, 162-175. https://doi.org/10.1145/3433210.3437517
[49] Rui Huang. amd-pstate cpu performance scaling driver. https://www.kernel.org/doc/html/latest/admin-guide/pm/amd-pstate.html . Accessed: 2024-12-30.